Auf dem Monitoringserver trat ein Problem auf, durch die hohe Changerate der Daten (ständig kommen neue hinzu, und im Idealfall werden alte gelöscht) ist nach einer gewissen Zeit die Indexfragmentierungsrate recht hoch ist. Die ist zwar nur ein theoretischer Wert, jedoch führt das in der Praxis tatsächlich zu höheren Laufzeiten bei einfachen Abfragen.
Im Extremfall dauerte die Abfrage (count(*)) gegen eine leere Tabelle Minuten. Da kann zwar auch ein korrupter Block im Spiel gewesen sein, jedoch ist das dann nur ein weiterer Grund für Heilung durch einen Index Rebuild, welcher dann letztlich das Problem löst.
Aus dieser Notwendigkeit sind mehrere Jobs entstanden.
Zunächst ein Job, der den akuten Befund „Abfrage auf Tabelle dauert viel zu lange“ ermittelt und einen Index Rebuild durchführt.
Dann entstand ein Job, der als Kriterium für den Reorg nicht eine vielleicht durch Seiteneffekte beeinflusste Laufzeit, sondern direkt die in die INDEX_STATS ermittelte Fragmentierung als Kriterium heranzieht.
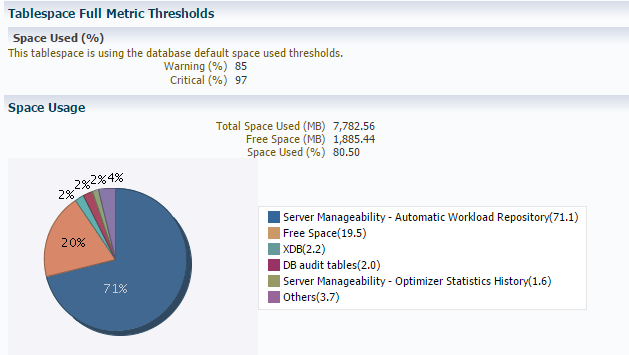
Die übliche empfohlene Schwelle für einen Rebuild ist ein Fragmentierungsgrad > 20%. Wir fanden teilweise 85% Fragmentierung vor.
( siehe MyOracleSupport How Btree Indexes Are Maintained (Doc ID 30405.1) )
File 2 -> INDEXWARTUNG_MITANALYZE.SQL
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 | SET SERVEROUTPUT ON SIZE 1000000 /* Analysiert für einzugebendes SCHEMA die Fragmentierunge der Indizes und wirft einen INDEX REBUILD ONLINE an. Dies hat sich als relativ sinnfrei erwiesen, da der ANALYZE schon die Tabelle lockt - und länger braucht als der Rebuild. So machen wir lieber einen Wartungsjob ohne Analyze mit nur Rebuild online! (s.u) Hier eine kleine Feinheit: Der Index wird in zwei Schritten analysiert, erst ONLINE, soll den Cache füllen, dann ohne ONLINE, erst dann wird INDEX_STATS gefüllt, was dann schneller erfolgt Leider sind die Objektgrößen hier im Monitor Schema jenseits gut & böse..., führt leider auch zu Locks, trotz gefülltem Cache */ DECLARE USERNAM VARCHAR2(30); INPUTSCHEMA VARCHAR2(30); NIND_NAME DBA_INDEXES.INDEX_NAME%TYPE; -- VARCHAR(30); NTAB_NAME DBA_INDEXES.TABLE_NAME%TYPE; --VARCHAR(30); FRAG VARCHAR(10); CMD VARCHAR2(500); CMD_ONLINE VARCHAR2(512); EXAMINE_ONLY NUMBER; REPORT_STAT NUMBER; NLOOP NUMBER; LINES NUMBER; FragRate NUMBER; Iname VARCHAR(30); DelRows INDEX_STATS.lf_rows%TYPE; --NUMBER TabRows INDEX_STATS.lf_rows%TYPE; --NUMBER BEGIN DBMS_OUTPUT.PUT_LINE('-- INPUTSCHEMA MUSS!! GEQUOTED EINGEGEBEN WERDEN '); USERNAM := &&INPUTSCHEMA; EXAMINE_ONLY := &&NODELETE; /* 0 ==> FALSE; 1 ==> TRUE */ REPORT_STAT := 1; DBMS_OUTPUT.PUT_LINE('-- Reportmode ist '|| REPORT_STAT); NLOOP := 0; -- Hauptschleife über die INDIZES FOR NIM_IND IN ( SELECT index_name, table_name FROM dba_indexes WHERE OWNER = USERNAM AND Index_type = 'NORMAL') LOOP NIND_NAME := NIM_IND.index_name; NTAB_NAME := NIM_IND.table_name; NLOOP := NLOOP + 1; DBMS_OUTPUT.PUT_LINE( NLOOP || ': INDEX ' || NIND_NAME); -- nicht zählen nur "ist mindestens eine Zeile da" CMD := 'SELECT COUNT(*) FROM (SELECT 1 FROM ' || USERNAM || '.' || NTAB_NAME || ' WHERE ROWNUM <= 1)'; EXECUTE IMMEDIATE CMD INTO LINES; DBMS_OUTPUT.PUT_LINE(NTAB_NAME || ' ZEILEN : '||LINES); IF LINES > 0 THEN --- Something to do? CMD := 'ANALYZE INDEX ' || USERNAM || '.' || NIND_NAME || ' VALIDATE STRUCTURE'; CMD_ONLINE := CMD || ' ONLINE'; DBMS_OUTPUT.PUT_LINE(CMD); -- Beschleunigung des Locking Statements durch Füllen des Caches EXECUTE IMMEDIATE CMD_ONLINE; EXECUTE IMMEDIATE CMD; SELECT name, lf_rows , del_lf_rows INTO Iname, TabRows , DelRows FROM index_stats WHERE name = NIND_NAME; IF DELRows > 0 THEN FragRate := 100*DelRows/Tabrows; Frag := TO_CHAR((100*DelRows)/TabRows,'999.9'); IF REPORT_STAT <> 0 THEN DBMS_OUTPUT.PUT_LINE(Iname || ' Rows: ' || TabRows || ' DelRows: '|| DelRows || ' Fragmented: ' || Frag); END IF; IF FragRate > 20 THEN CMD := 'ALTER INDEX "' || USERNAM || '"."' || NIND_NAME || '" rebuild ONLINE'; IF REPORT_STAT <> 0 THEN DBMS_OUTPUT.PUT_LINE(' ****** Fragmentierungsgrad ' || Frag || ' zu hoch, Index Reorg ist erforderlich '); END IF; IF EXAMINE_ONLY = 0 THEN DBMS_OUTPUT.PUT_LINE(' REORG CMD: ' || CMD); EXECUTE IMMEDIATE CMD; COMMIT; END IF; END IF; -- FragRate ELSE --DELROWS DBMS_OUTPUT.PUT_LINE(Iname || ' 0 gelöschte Zeilen -> keine Fragmentierung '); FragRate := 0; END IF; -- DELROWS END IF; -- LINES END LOOP; -- NUM_TABLES; END; / EXIT |
Leider ist das Ermitteln der validen Indexstruktur maßgeblich teurer als meist der einfach Reorg.
(einleuchtende Erklärung https://blog.pythian.com/analyze-index-validate-structure-dark-side/)
Als Zwischenlösung gibt es einen einfachen Trick der im obigen Script angewandt wurde.
Zunächst ein
analyze index ix validate structure online;
der die Tabelle nicht lockt, jedoch auch INDEX_STATS nicht füllt, gefolgt von einem
analyze index ix validate structure;
DIe Hoffnung ist, jetzt sind die Daten im Cache und der die Tabelle lockende ANALYZE dauert nicht so lange.
Da dies jedoch mit den überaus großen Objekten des Monitoringsschemas unter Produktionsbedingungen nicht funktioniert hat, letztlich ein Job der einfach alle Indizes eines Schemas neu aufbaut.
Dies kann interaktiv erfolgen, oder je nach Bedarf in einem Zyklus. Ein Wartungsfenster ist nicht erforderlich, da der Job die Objekte nicht lockt. Davon würde Job2 profitieren, in einem Wartungsfenster ohne produktiven Betrieb wäre ein VALIDATE STRUCTUR als Kriterium des Rebuilds hilfreich, und dieser könnte ohne Lock durchgeführt werden.
Doch jetzt der Bulk-Job:
Script 3 -> INDEXWARTUNG_BULK.SQL
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 | SET SERVEROUTPUT ON SIZE 1000000 /* Wartungsjob: für einzugebendes SCHEMA wird ein INDEX REBUILD ONLINE angeworfen. Dies ist bei Objekten deren Analyse teuer ist, die effektiveste Variante. */ DECLARE USERNAM VARCHAR2(30); INPUTSCHEMA VARCHAR2(30); NIND_NAME DBA_INDEXES.INDEX_NAME%TYPE; -- VARCHAR(30); NTAB_NAME DBA_INDEXES.TABLE_NAME%TYPE; --VARCHAR(30); FRAG VARCHAR(10); CMD VARCHAR2(500); CMD_ONLINE VARCHAR2(512); EXAMINE_ONLY NUMBER; NLOOP NUMBER; LINES NUMBER; FragRate NUMBER; Iname VARCHAR(30); DelRows INDEX_STATS.lf_rows%TYPE; --NUMBER TabRows INDEX_STATS.lf_rows%TYPE; --NUMBER BEGIN DBMS_OUTPUT.PUT_LINE('-- INPUTSCHEMA MUSS!! GEQUOTED EINGEGEBEN WERDEN '); USERNAM := &&INPUTSCHEMA; EXAMINE_ONLY := 1; EXAMINE_ONLY := &&NOWRITE; /* 0 ==> FALSE; 1 ==> TRUE */ NLOOP := 0; -- Hauptschleife über die INDIZES FOR NIM_IND IN ( SELECT index_name, table_name FROM dba_indexes WHERE OWNER = USERNAM AND Index_type = 'NORMAL' AND TABLE_NAME IS NOT NULL ORDER BY INDEX_NAME ) LOOP BEGIN -- cause excepzion NIND_NAME := NIM_IND.index_name; NTAB_NAME := NIM_IND.table_name; NLOOP := NLOOP + 1; DBMS_OUTPUT.PUT_LINE( NLOOP || ': INDEX ' || NIND_NAME); IF 0=1 THEN -- DOCH NICHT COUNT ausführen -- nicht zählen nur "ist mindestens eine Zeile da" CMD := 'SELECT COUNT(*) FROM (SELECT 1 FROM ' || USERNAM || '.' || NTAB_NAME || ' WHERE ROWNUM <= 1)'; EXECUTE IMMEDIATE CMD INTO LINES; DBMS_OUTPUT.PUT_LINE(NTAB_NAME || ' ZEILEN : '||LINES); ELSE LINES := -1; END IF; IF LINES <> 0 THEN -- In Sonderfällen kann es nötig sein, trotzdem zu reorganiseren. Dann manuell! --- Something to do? CMD := 'ALTER INDEX "' || USERNAM || '"."' || NIND_NAME || '" rebuild ONLINE Nologging PARALLEL 4 '; DBMS_OUTPUT.PUT_LINE(' REORG CMD: ' || CMD); IF EXAMINE_ONLY = 0 THEN DBMS_OUTPUT.PUT_LINE(' EXECUTING CMD '); EXECUTE IMMEDIATE CMD; COMMIT; END IF; END IF; -- LINES EXCEPTION WHEN OTHERS THEN BEGIN IF SQLCODE = -942 THEN -- http://www.dba-oracle.com/sf_ora_00942_table_or_view_does_not_exist.htm DBMS_OUTPUT.PUT_LINE (' Misc.Problem Tabellenobjekt ' || NTAB_NAME ); END IF; DBMS_OUTPUT.PUT_LINE ('Abgefangener Fehler : Errcode ' || SQLCODE); GOTO END_LOOP; END; -- EXCP END; <<END_LOOP>> NULL; END LOOP; -- NUM_TABLES; END; / EXIT |



")


")


")


")