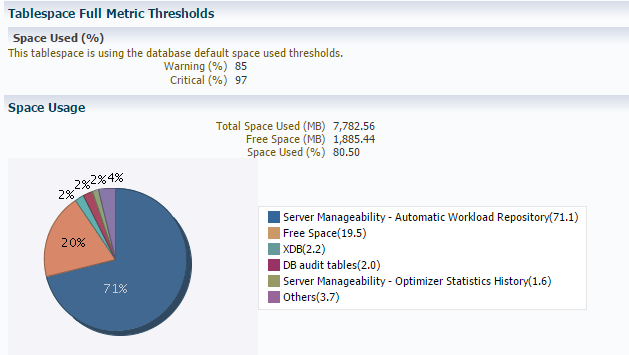
Hier fällt sofort der exzessive Speicherbedarf der AWR Daten auf. Bei einer DB ohne Größenwachstum durch die Nutzerdaten ist es sehr unangenehm, wenn SYSAUX in die Größenordnung der Daten kommt.
Dies ist der allgemeine Beitrag zu diesem Thema. Am Ende des Beitrags finden Sie einen Link zu dem detaillierten Beitrag (mit Source der Scripte)
Oracle 11g SYSAUX Growth, Bug 14373728 „Old Statistics not Purged from SYSAUX Tablespace“
Beim Betrieb von etlichen Datenbanken, gemischt Oracle 11.2.0.4.3 sowie 12.1.0.2.1, fielen im Vergleich die 11g Datenbanken durch exzessives Größenwachstum in SYSAUX auf – bei gleicher Datenlage wie eine entsprechend auf 12c aufgesetzte DB waren gigabyteweise mehr Daten im Tablespace SYSAUX vorzufinden.
Detailanalyse zeigte dann auf, dass die anwachsenden Daten unter „Automatic Workload Repository“ – AWR geführt sind.
Piechart SYSAUX
Der folgende Link weist auf einen Artikel von Frau Held hin, eine hervorragende Fundstelle, die die dem Problem zugrunde liegenden Ursachen beschreibt.
Dieser Beitrag hier geht noch etwas weiter und beschreibt die Möglichkeiten, eine Maschine zu bereinigen, die schon soviel Daten angehäuft hat, dass die Standardprozeduren in Resourcenprobleme laufen.
Ursache ist ein Bug, der scheinbar in der SOLARIS Release nicht gepatcht war:
Oracle Bug 14373728 Description
Auswirkung:
Liste nach Objektgrösse
Diese Übersicht kommt aus dem EM. Man kann sie sich auch manuell holen:
Select * from v$sysaux_occupants order by SPACE_USAGE_KBYTES DESC
Liste der Objektgrößen – script
Wir sehen hier eine Vielzahl von Tabellen und Indizes (partitioned), die definitiv zu groß sind.
Über awrinfo kann man sich die zu erwartenden Größen anzeigen lassen.
Das awrinfo.sql script findet man im $ORACLE_HOME/rdbms/admin directory
Dort findet man auch eine Schätzung der zu erwartenden Größen des AWR-Bereichs aufgrund der eingestellten Retentionparameter. Üblich ist z.B. ein stündlicher Snapshot für 7 Tage oder 30 Tage.
Die Informationen kann man sich natürlich auch dediziert holen:
SELECT DBID, MIN(SNAP_ID), MIN(BEGIN_INTERVAL_TIME), MAX(SNAP_ID), MAX(BEGIN_INTERVAL_TIME)
from dba_hist_snapshot group by dbid;
Verändert werden können die Parameter, die die Frequenz der Berechnung und Aufbewahrungszeit steuern, zum Beispiel so:
— change retention time
— this is in minutes chg to 4d
exec DBMS_WORKLOAD_REPOSITORY.MODIFY_SNAPSHOT_SETTINGS(retention=>5760);
Aufgrund eines Bugs in der Release 11g kommt es jedoch vor, dass der physische Speicherbedarf unlimitiert anwächst, da alte Snapshots nicht entfernt werden.
Diese müssen dann manuell entfernt werden. Dafür gibt es eine Standardprozedur:
Zu füttern ist der Aufruf mit der DBID sowie dem Range der verwaisten Snapids. Später liefern wir ein Script, mit dem man diese ermitteln kann.
Ausgabe Simplescript:
Partition_name WRH$_ACTIVE_413047826_8381
i 1 dbid 413047826 : WRH$_ACTIVE_413047826_8381 MinInPartition 8381 MaxInPartition 8404
—
Anzahl verwaister Records ist 6253 MinOrphaned is 8381 MaxOrphaned is 8403
—
Executing: DBMS_WORKLOAD_REPOSITORY.DROP_SNAPSHOT_RANGE ( low_snap_id ->8381; high_snap_id ->8403; dbid ->413047826);
simple script kann DROP_SNAPSHOT_RANGE direkt aufrufen, das ist die Komfortlösung.
Ausgabe Detailscript:
DBID in DBA_HIST_WR_CONTROL 413047826
–
===0> Hier stehen die inkonsistenten Daten für das manuelle Delete ==>
DBID in WRH$_EVENT_HISTOGRAM 413047826 MIN SNAPID 8381 MAX SNAPID 8403
–
===0> Und hier stehen die aktuellen Daten für den zeitnahen Bereich ==>
DBID in DBA_HIST_SNAPSHOT 413047826 MIN SNAPID 8404 MAX SNAPID 8611 MINT 26.10.17 00:00:43,119
Die Werte für den Aufruf von DROP_SNAPSHOT_RANGE kann man hier direkt ablesen und einsetzen.
Im Normalfall wäre man dann schon fertig.
Leider passiert es, wenn die Datenbanken längere Zeit, viele Monate ohne diese Pflege laufen, dass sich soviele Daten in SYSAUX AWR ansammeln, dass die DROP_SNAPSHOT_RANGE-Procedur in solch große Resourcenprobleme kommt, dass das Ganze nicht mehr handelbar ist.
Dafür haben wir dann ein Script gebaut, das resourcenschonend Objekt für Objekt in handlichen Chunks löscht (jeweils commited), und dies in von außen begrenzbaren Iterationen. So konnten wir letztlich das Größenwachstum in den Griff bekommen.
Webseitenbetreiber müssen, um Ihre Webseiten DSGVO konform zu publizieren, ihre Besucher auf die Verwendung von Cookies hinweisen und darüber informieren, dass bei weiterem Besuch der Webseite von der Einwilligung des Nutzers
in die Verwendung von Cookies ausgegangen wird.
Der eingeblendete Hinweis Banner dient dieser Informationspflicht.
Sie können das Setzen von Cookies in Ihren Browser Einstellungen allgemein oder für bestimmte Webseiten verhindern.
Eine Anleitung zum Blockieren von Cookies finden Sie
hier.




")


")